子供が1歳になった振り返り
はじめに
子供(男の子)が1歳になるまでにやって良かったこと、買って良かったものなどメモを残す。
教育方針

「フランス式育児」を参考に、「自立を促す」をテーマにおいた。
ただ「妻(産んだ側)」と「夫(産んでない側)」の意識は違うという理解は必要。
夫は論理的に「これいらなくない?」って思うかもしれないが、妻は心配性になっているので、そこはうまく尊重しながら進めて行くことが大事。
寝る: 0歳
寝かしつけがしんどいという話は常々聞いていたので、ネントレ(ねんねとレーニング)として病院から戻ってきた時から、別々の部屋で寝かせた。
結論から先に話すと、ほぼ寝かしつけをしてない。今1歳半だけど、ベッドや置いたら勝手に寝る(昼寝も勝手に寝る)状態なので、とても楽。
最初に買ったベビーベッドとバウンサーはこれ
")

バウンサーは昼寝のときにずっと使ってた。最高。
木だと捨てるのが大変なので、捨てやすいものを選んだ。
隙間があるものだと、足を引っ掛けて事故になるかもしれないので避けた。
夜寝る場所が真っ暗なので、昼寝時はリビングに移動させたかったので、キャスター付きを選んだのはとても良かった。
頭の形を良くするために枕も買ったけど、まぁほぼしないのでなくて良かったかな。
パジャマは上下別々ではなく、オールインワンのものが最高。西松屋で買ってた
スワドルも試したけど嫌がってダメだった
布団は息できなくなる可能性があるため、布団なしでエアコンで温度調整していた。
うるさい中でも寝れる訓練をしたほうがいいと言われたので、最初は静かにテレビを見てたりしてたが、徐々に笑い声や話し声も普通にした。
寝る: 1歳
体重が重くなってきたので次はこのセットを買った。
")
ベビー敷ふとん レギュラータイプ 1513-07022")
 ベビー 洗濯機で洗える羽毛掛け布団 保温に優れた 厚手タイプ 秋冬に 95X120cm ベビーホーム 日本製 1512-00136")
 お昼寝 ごろ寝クッション 座布団 軽量 コンパクト 折り畳み キャンプ 車中泊 HD93995501")
 デジタル温湿度計 環境チェッカー ミニ ホワイト 73244")
 加湿器 ハイブリッド式(木造和室40畳まで/プレハブ洋室67畳まで) PCタイプ パワフルモデル ホワイト HD-PC2400G-W")
オネショはほぼないが、たまにうんちが溢れてしまってた(お腹くだしてるときとか)ので、全体的に洗えるもので揃えたのはとても良かった
オネショシーツなどは西松屋で適当に買った。
寝る時のカメラは買わなかったけど、困ることはなかった
寝る時のパジャマは基本的にに西松屋やユニクロでコットン100%を見つけて買った
意識してたのは、二度寝の練習をさせてたくらい。
あと昼寝時は地べただと身体が痛そうなので、ごろ寝マットが最高。よくこの上で寝てた
食べる: ミルク編




![【旧品】明治ほほえみ らくらくキューブ 540g (27g×20袋)[0ヵ月~1歳頃 固形タイプの粉ミルク]](https://m.media-amazon.com/images/I/51yG6dhypVL._SL500_.jpg "【旧品】明治ほほえみ らくらくキューブ 540g (27g×20袋)[0ヵ月~1歳頃 固形タイプの粉ミルク]")
【日本製】 煮沸・レンジ・薬液OK 小さめの哺乳瓶にもすっぽり入るスリム設計 (グレー)")
母乳を全く飲まなかったし、搾乳機やったけどあまり出なかったので、ほぼオールミルクでやった。
哺乳瓶はいくつか試したけど、これだけ飲んでくれた。
粉ミルクに付随してるスプーンは小さめで、子供が大きくなると何度も注ぐのがめんどくさいので、100ml用のスプーンは必須
最初は100℃のお湯でミルクを溶かし、氷水の入った容器で冷やしてあげていたが、これだとあげるのに5分くらいかかる。
途中から70°のお湯で粉を溶かして(サルモネラ菌対策)、その後水を入れて温度を調整して飲ませてた。このやり方は最高だったが、妻の抵抗(心配)があるので、いかに楽かを体験させることで解決した(1日で解決した)
温度調節できる電気ケトルはめちゃくちゃ重宝した
飲み終わったらスチーム除菌機に入れて回すだけ。洗浄 + スチーム除菌 + 乾燥機もついて、とても最高だった。
食べる: 離乳食編





スプーンは広めがベスト。小さいと何回も口に運ばないといけないので疲れる
リッチェルのクネクネしたスプーンは、使うのがしんどかったので、あまりお勧めしない。
机にくっつける空中に浮くやつは怖かったので、ハイチェアにした。
物は廃盤になったベビービョルンのもので、ベルトもあり安定感もありずっと使えてるので最高。
朝はあんぱんまんミニスナックをあげてた
夕方、夜は離乳食で、じゃこご飯、いちご豆腐、ほうれん草バナナ、にんじん茹でて細かく砕いたやつなど。
親と味覚が似るので、親が嫌いなものは子供も嫌いなことが多いので避けた。
また、大人が食べても美味しくないものは子供も嫌がるのでこれも味見してあげてた。
離乳食教室で作るものは味が薄すぎて美味しくないので、子供は食べない。これは野菜が嫌いなのではなく美味しくないから食べない可能性があるので、美味しいもので栄養が高いものを作ってあげること。
食べる: 通常の食事編
")
![[ベビービョルン] ベビー スタイ パウダーブルー フリーサイズ単品 首回り無段階調整可能 わずか66gの超軽量設計 (シリコン不使用)](https://m.media-amazon.com/images/I/31IJq5Da6pL._SL500_.jpg "[ベビービョルン] ベビー スタイ パウダーブルー フリーサイズ単品 首回り無段階調整可能 わずか66gの超軽量設計 (シリコン不使用)")
")
![【2025年版/1歳~/持ちやすい/ケース付】tecopeco[テコペコ] 赤ちゃん スプーン フォーク セット 持ち運びに便利なケース付き 離乳食 食器 ベビーカトラリーセット (グレージュ)](https://m.media-amazon.com/images/I/31xxgomUCzL._SL500_.jpg "【2025年版/1歳~/持ちやすい/ケース付】tecopeco[テコペコ] 赤ちゃん スプーン フォーク セット 持ち運びに便利なケース付き 離乳食 食器 ベビーカトラリーセット (グレージュ)")
 アクリア おでかけストローマグR 200 ネイビーブルー 1個 200ml 7カ月")
朝はトースト焼いて、バナナ半切れ、卵を死をかけて焼いたのが基本。
あとは親が食べるものに、砂糖や塩などを抑えて、細かく切ってあげてた。
フォークは1歳半以降くらいに徐々にできるようになった。それまではずっと手づかみ。
なのでよく手を石鹸で洗ってた。
なぜか知らないけど、この歳で乾杯を覚えてよくやってた。
トイレ
![メリーズ 【パンツ Mサイズ】 ずっと肌さらエアスルー (6~11kg)186枚 (62枚×3) [ケース品] 【Amazon.co.jp限定】](https://m.media-amazon.com/images/I/51vvCkHV10L._SL500_.jpg "メリーズ 【パンツ Mサイズ】 ずっと肌さらエアスルー (6~11kg)186枚 (62枚×3) [ケース品] 【Amazon.co.jp限定】")
![カークランドシグネチャー [コストコ] 赤ちゃん用 おしりふき 900枚](https://m.media-amazon.com/images/I/51N9aUsi8VL._SL500_.jpg "カークランドシグネチャー [コストコ] 赤ちゃん用 おしりふき 900枚")

 うんちが臭わない袋 2個セット 猫用うんち処理袋【袋カラー:ブルー】 (Mサイズ 90枚入)【販売元をご確認ください 中身を箱から出して出荷されるケースが発生しています】")
おむつは色々試したけど、安すぎると漏れることがあるが、パンパースだと高いのでメリーズに着地。
おしっこはゴミ箱、うんちは匂いが強いので猫用のゴミ袋に入れて捨ててた。
コストコのおしり拭きは大きめで大量に入ってるのでマジでおすすめ。これがないとやってけないレベル。
お風呂
新生児 バスマット 乾きやすく洗いやすい 滑り止め やわらかい 安全 快適 エコ")

 ベビー全身シャンプー 本体ボトル 350mL ソープ 赤ちゃん 0歳から使える 泡タイプ 保湿 乾燥対策 弱酸性 低刺激性")

![Mama&Kids ママ&キッズ ベビーミルキーローションお得用サイズ 380ml ポンプタイプ [ 低刺激スキンケア ]子供用 弱酸性 無添加 無香料 保湿 ベタつかない](https://m.media-amazon.com/images/I/31yvvgThnuL._SL500_.jpg "Mama&Kids ママ&キッズ ベビーミルキーローションお得用サイズ 380ml ポンプタイプ [ 低刺激スキンケア ]子供用 弱酸性 無添加 無香料 保湿 ベタつかない")

")
座れるまではリッチェルの発泡スチロールのバスチェア。
座れるようになったらSKIP HOPのバスチェア。
うちは髪用と身体洗う用でソープを分けていた。そのためか髪はふさふさ。
あわぴよとかも試したけど、ボツボツができやすかったのでミノンにした。
ボディーミルクも安いのより高い方がボツボツ出来にくいので高めのやつを買ってた。
最初の頃はガーゼハンカチで洗ってたが、弱めのシャワーでいけるタイミングを常に模索したほうがとても楽になるので、チャレンジしていくのが良い。
鼻水吸い取りは必需品。
髪を切る
![[JASDESIGN] 散髪ケープ 毛染めケープ メイクケープ シャンプーケープ ヘアカラーケープ ヘアカット カラーリングケープ 黒 JM-233](https://m.media-amazon.com/images/I/31sfmSYU4GL._SL500_.jpg "[JASDESIGN] 散髪ケープ 毛染めケープ メイクケープ シャンプーケープ ヘアカラーケープ ヘアカット カラーリングケープ 黒 JM-233")


お風呂場で抱えてもらいながら切ってた。
めっちゃ子供の髪の毛を切る動画を見てた。
遊ぶ
)")
")
 ベビー・プレイネスト 3ヶ月頃から (同梱:チューブ カバー 空気入れ 組み立て説明書) GT3200345")

 パステルカラーが可愛い ( 音が鳴る / ぴかぴか 光る ) 0歳 1歳 2歳 赤ちゃん向けおもちゃ")

 レインフォレスト・デラックスジムII 【0カ月~】【知育玩具】【布おもちゃ】DFP08")
プレイマットはあった方が安心で良い。PREMA一択。
おもちゃはおすすめだけ載せる。
出かける


![[タバラット] ちょうどいい タオルハンカチ ハンドタオル ハンカチ 22.5×23cm Tps-152R (3枚, 3色アソートA)](https://m.media-amazon.com/images/I/51yN0EH7UjL._SL500_.jpg "[タバラット] ちょうどいい タオルハンカチ ハンドタオル ハンカチ 22.5×23cm Tps-152R (3枚, 3色アソートA)")
")
")

抱っこ紐はアーティホッペの高いのを買った。
ベルト部分が外れてもゴム紐で防げるし、おしゃれだからが理由。
ベビーカーも高いのを買った。
よく使うのでってのが理由。あとは軽さ。アカチャンホンポでいっぱい試してこれにした。
化粧ポーチはでかけるのに必需品。次を必ず入れてた
- おむつ *3枚
- おしり拭きの小さめ
- 匂わないゴミ袋 *4枚
- 外出用キューブミルク(ほほえみ)
- おやつ
ハンドタオルは外出用としておしゃれなやつを買ってた。
基本的に「人に迷惑をかけない」ために、人混みの時間帯や遊びに行くためだけの外出は避けてた。
生まれたのが夏の時期で、熱中症に気をつけてたのもあったかもしれない。
外食も避けているので、家でフレンチ作って楽しめるようにしてる。
服
)")
基本的に西松屋。最近はアカチャンホンポのほうがちょっと高いけど質がいいそっちにしている。
大きくなるまでは上下1セットになってるやつがおすすめ。インナーも。
よだれかけは2歳くらいまでめっちゃ使うので、いいやつ買うと良い。
保育園・プリスクール
引っ越す前は保育園に預けてたが、引っ越した後は待機児童になったため、プリスクールの選択肢しかなかった。
プリスクールは全部英語にはなるが、特に問題はないが、補助は出るというものの高い。
あとは結構自立を促してくれるのがとても良い。
夫婦
うちの子供は寝たら起きないので、寝終わったらwebカメラ等で定期的に見ながら、軽く散歩したり、コンビニに行ったり息抜きをしてた。
息抜き本当に大事。これがないと引きこもってばかりになってやってけない。(あまり表で言えないがこれが育児の現実だと思う)
そして男性へのアドバイス。
- うまい料理を覚えて奥さんに作ってあげよう
- 女性より率先して育児を学んで、メモを取ろう
- いっぱい調べて、他の人のアドバイスを参考にしよう
- 赤ちゃん言葉はやめて、子供を1人の人間、大人みたいに見てあげよう
次の女性のアドバイス。
- 信頼して男性の思うように一回やらせてあげてほしい。新しい良い発見が出てくるよ
- 失敗してもあまり怒らないこと。その後自分自身も失敗することもある
- 子供の離乳食、ご飯は大人でも美味しいものを作ってあげて。砂糖なくても味醂で甘くなるよ
- 赤ちゃん言葉はやめて、子供を1人の人間、大人みたいに見てあげよう
DXERのCTOとして1年やったこと(実務編)
CTOになって1年くらい経ったので実際に実務何をやっているのかというあたりを話そうと思ってます。
会社の戦略、経営に関するものは https://note.com/sion_cojp/ にどこかで書きます。
- TL;DR
- なんの会社やってるの?
- コードは書いたり書かなかったりしている
- PdMを一時やっていたが辞めた
- スクラム開発をやめたけど、また始めた
- デザインをやっていたがやめた
- はじめてのFigma
- 全部署、全メンバーのマネジメントと業務をしている
- ビジネスモデルを確立するために
- 経営チームとして
- 実務
- 最後に
TL;DR
- メインプロダクトは設計・レビューのみ、その他部署のためのコードを書いてる
- PdM + デザインをやったけど権限委譲していってる
- 全部署、全メンバーのマネジメントと業務をしている
- ビジネスモデルを確立するために、全部署のプロセスを作っている
- 会社や事業の思想・戦略を立てて実行していってる – 実務は全ての部署の作業をやっている
- やはりスタートアップは楽しい
なんの会社やってるの?
シスクルという、情シス代行サービスと、それに付随したSaaSの提供を行ってます。
情シスがいる or いない会社でも、我々が「御社の従業員の1名のように、情シス業務(IT業務)を行います」
初期費用なし + 従量課金で提供しているので、是非お問い合わせください
コードは書いたり書かなかったりしている
最初はメインプロダクトとなるSaaS(Go x GraphQLとNext.js)のコードを書いてましたが、最近SaaSは他メンバーに移譲し、CTO兼ドメインエキスパートとして設計に関わるようにしてます。
権限委譲したのは、私のタスクが過多になっているのと、開発チームで顧客の課題を提供するので、それを考えてもらいたいためですね。
コードは引き続き書いており、様々な部署で必要なコード(Chrome Extension(React)やツール(Go))を書いています。
PdMを一時やっていたが辞めた
辞めた理由は、ある程度ベクトルを示せた + 他の職責をやる必要があったので権限委譲したからです。
基本的には https://productschool.com/resources/templates にあることを取捨選択してやってただけで、
大事なのは「現場の負担を抑えながら、正しく推進力を出すこと。情報は自身でPullして把握すればいい」と思ってやっていました
下記のようなPRDテンプレートを用意し、それに沿って書いて進めていた結果、認識齟齬が圧倒的に減ったので良かったです。
特徴的なのは、PRDの段階でBack/Frontで切るべきチケットまで定義してるところですね。途中で必要になったら別途切ってもらえればいいです。
なぜそこまで細かくやっていたかというと、「情シスという難しいドメイン + 初期はこれくらいやらないと推進力がなかったから」です。
1. 概要
2. 目的
3. 別サービスの参考画像/動画
4. SLI
5. ユーザシナリオ
7. 機能でやること
- frontend
- backend
8. 機能でやらないこと
9. Design/UserFlow
10. Q&A
11. Reference
スクラム開発をやめたけど、また始めた
上に付随するのですが、スクラムを一時期やめてトップダウンにしました。
理由とやった結果は下記
# 理由 - 業務委託が中心なので、工数があまり測れない - スクラムに関わる会議を減らして、エンジニアの稼働を増やしたい - スクラムのメリットを感じてない。むしろ負荷 - 情シスという難しいドメイン + 初期はこれくらいやらないと推進力がなかった # やった結果 - 推進力が上がった: PRDベースにgithub issueにチケットを切っているので、あとはやるだけ。 - 早めに問題が発見出来る: コミュニケーションで解決し、迷ったときの最終ジャッジはPdMの私。 - 見積もりはしにくい: 細かく見積もるメリットが当時なかった(流石に遅いと突っ込んでます)
最近になって権限委譲を行い、再びスクラム体制に戻しました。
理由はある程度軌道に乗ったので、そのほうが顧客の課題に最短距離で解決でき、また開発メンバーに顧客のペインに向き合ってほしかったからです。
どう顧客のペインをコミュニケーションするかは、専用のslackチャンネルを設け議論しあう仕組みにしました。

デザインをやっていたがやめた
やめた理由はある程度大枠が出来たから、あとはどういうUIにするかは現場に任せました。
細かくFigmaでデザイン設計すべきだとは思いますが、私の工数が足りないので諦めたのもあります。
なのでFigmaのデザインは頭出し移行updateされてないです。
私がやったことは、MaterialUIベースでSaaSをデザインを一から作り直しました。
「どんなUIになるのか?」最初はmiroで適当な下書きをしていましたが、下記課題を解決するため、私がFigmaで作ることにしました
- プロダクトを円滑に進めるため、もっと細かいレベルのデザイン設計が必要だった - チームからあったほうがやりやすいと言われた - 事業ドメインの複雑性が起因
はじめてのFigma
ぶっちゃけFigma触ったこと無いので、勉強しながら2~3週間くらいで設計完了しました。
Material Designってワードだけは知ってたのですが、完璧に理解できてなかったので、ドキュメントとFigma Communityのテンプレートを利用 + 社内の精通者に進捗報告しながら勉強していきました。
当時は現場から「良さそうに進んでる」と評価いただいてます。
また今回からMaterial Design 2 x MUI → MaterialDesign 3 x Tailwindに変わったので、カラースキーマやテキストもTailwindデフォルトベースにしました。
そこら辺の技術背景、選定、このFigmaの存在意義などは、FigmaにIntroductionページを用意し、全部書くようにしてます。
storybookと連携しないといけないと思いつつ、そこはちゃんとしたデザイナーが雇えたら考えていいでしょう。
色やボタン、ナビゲーションの定義、またそれぞれをコンポーネントで一元管理し、修正しやすいを意識してましたね(色変えたら全部変わるみたいな)



全部署、全メンバーのマネジメントと業務をしている
組織を良くするためにマネジメントをする課題があり、私がやっております。
主にOODAベースでやってますが、私のマネジメント手法は深いので、別途どこかで紹介出来ると面白いかと思います。記事書きます。
社内のアウトプットとしては、どう分析し、アクションしているを必要なメンバーに共有し、いずれ担ってくれれば嬉しいなと思ってます。
ビジネスモデルを確立するために
全部署で、どういうプロセスが必要か or 確立する必要があるか。
私が先陣きり、mermaid記法で全て洗い出し、作成し、必要な方々にレビューしてもらってます。
作るのもしんどい作業ですし、レビューもしんどい作業ではありますが、これがビジネスの基盤になるのでしっかりとやってます
経営チームとして
Service Idea Docというものを書き起こしました。
「なぜこの会社、事業が存在するのか?」というものを定義した1枚ページです。
迷ったらここを見ろってやつですね。
会社と事業単位に1つずつ存在します。テンプレートは下記。
1. この記事のゴール 2. Story 3. Purpose 4. Mission 5. NSM 6. KGI 7. TargetUser 8. 戦略 - 長期戦略 - 中期戦略 9. ロードマップ 10. 全員が理解し顧客に説明できるようになるべき資料 11. エンジニア資料 12. その他 13. Reference
あとは戦略を色々考え、予測し、実行に移して入るのですが、それは sion_cojp|note にでも書きます。
実務
私の作業としては、今は全ての部署の作業をやっています。
経営、営業、エンジニア、カスタマーサクセス、カスタマーサポート、人事労務、採用...
CEOの@TakumaMukai も同じ感じで、人が足らず頑張ってます。
とてもハードではありますが、スタートアップはこういうものでしょう
最後に
私の気持ちとしては「このタイミングに行けば絶対売れ、いずれ世界が変わる」と確信はしているので、頑張っていきます。
CEOの@TakumaMukaiには大変迷惑かけてると思いますが、アドバイスと方向性を示してもらったり、一緒に色々作り上げていけてることに、とても感謝。
また今いるメンバーも気を遣ってもらったり、会社の成長の一役買っていただいてとても感謝。
そしてやはりスタートアップは泥臭くてハードだけど楽しいなぁという気持ちが強いです。
やるべきことがたくさんありすぎて、もっと人を増やす必要があるので、もし興味がある方は下記JD見て応募いただくか、カジュアル面談しましょう!
SREとバックエンドを統合してバックエンドに転向しました
はじめに
タイトルの通り、SRE歴だと6年 + 5社目ですが、株式会社チカクのSREからバックエンドに転向して2ヶ月経ちました。
この2ヶ月、フェーズが変わったプロダクトに追従出来ていなかったチームの開発プロセスを刷新することにメンバーと注力していました。
それについてお話しします。
SREを無くした
「SREはバックエンドが分かってないと信頼性を担保することは出来ない」
「バックエンドはインフラが分かってないとインフラを意識した設計、冪等性の担保、柔軟でベストな設計が出来ない」
と私は考えており、少人数で複雑なアーキテクチャでなければSREとバックエンドを分離する必要はないと思ってます。
またSREとバックエンド双方に課題があったことから、
ようやくこのタイミングでSREとバックエンドを統合することを、会社的にも良いと判断しそのような体制にすることができました。
SREの課題
弊社SREは私1人で運用していますが、ドキュメント化やdrawioで図にされており、
make apply .... と叩けば誰でもterraformが打てる環境だったりPull Request welcome状態なのですが、
課題として役割的にも知見的にもやりたがる人がいないことでした。
結果、私の知見がドキュメントベースで蓄積するだけで他メンバーのaws, terraformの経験が成熟せず、awsコンポーネントを用いた設計するときがSPOFになる状態でした。
バックエンドの課題
社内事情が色々あって仕方ないタイミングだったと思いますが、「言語とフレームワークは選んだのであとはよろしく」と急に依頼がくるというカオスな状態でした。
「運用するための必要な修正が難しい場合はSREに依頼がくる」ことが多かったり、またDB migrate方法もSREが確立しなければなりませんでした。
なので選ばれた言語/フレームワークを理解する必要があり、これは結構しんどかったので最初の設計段階から関与する必要がありました。
cron(定期実行batch)に関しても「冪等性を担保してないので多重実行禁止だけど、数分単位で動く」というケースもあります。
おそらく「冪等性はインフラレイヤで担保してくれるだろう」という考えからだとは思いますが、ロック機構を作ってまでインフラレイヤで担保するかというところから議論したい気持ちではあります。
個人的には第一にバックエンド側で担保。どうしても無理ならインフラレイヤで担保するのが良いですね。
数分単位で動くのであればデーモン化 + job queueシステム。そんなに実行しないのであればcronにするのがベストだと思ってます。
他にも色々課題が山積みで、あとの項目でも一部紹介します。
SREとバックエンド統合してどうなった?
アーキテクチャ設計段階でSREとバックエンド双方の知識を保有してレビューをするので上記課題も解決できました。
設計時は、全バックエンドメンバーでシーケンス図(mermaid記法)をリアルタイムに書きながら議論し合える環境にしたのも良かったと思います。
課題としてはterraformのコードの質ですね。
terraformはresource名や設定が破壊的変更になったりするので、そこのネームスペースや依存関係をいかに考えて実装しないとサービス断が発生します。
そこは経験かと思います。
バックエンドに転向して何したの?
1. 開発体制を変えた
まず少人数なので性善説ベースで。READMEや自明なものはどんどんセルフマージしてOKにしました。
もし何かあったらその人の責任で、責任分散の意図でレビュー依頼をしましょうというルールです。
Pull Requestに関しては、今までは何も書いてないPRが多かったのですが、絶対書くべき項目として「概要と動作確認」を用意しました。
issueベースでPRがあればベストです。
レビューコメントは「feature/imo/yagni/nits/must」使いつつ、must以外はapprove。
これらに関しては、mergeスピードが速くし開発スピードをあげたい、PRにログ(挙動)を残したい、宗教的論争をなくしたいのが目的です。
実装があってればリファクタコメントはimoにして、気になる人が直せば良いです。
私はこんな感じでレビューコメントをしてたりします。

2. service design docを書いた
のような、サービスを立ち上げる際に必要なチェックリストです。
「自分たちは自明なことでも、PdMやその他エンジニアがこのシステム大事なことをみれば分かりやすく書く。深ぼりたいときはコードを読む」を意識してます。
現在のリストはこちら。ここから成熟していけたらと思ってます。
- サービス - Sequence Diagram - aws architecture diagram - バックグラウンド - ここに存在するサービスがなぜ必要なのか - 技術 - 言語 - ルーティング - ORM - AWS - Monitoring - 目標と非目標 - やること、やらないこと - インターフェイス - HTTPならURIをまとめたもの(swagger)のリンクを貼る - 依存関係 - SLO - データベース - 使ってるDBと権限 - バックアップと復旧 - RTO(目標復旧時間) - RPO(目標復旧時点) - PI/PII - セキュリティに関する考慮事項 - リファレンス - このリポジトリを利用する上で参考になるurl
3. Rails, DjangoからGoに移行した
弊社ではRails, Djangoのフレームワークを利用してますが、まずこのような課題がありました。
自由にカスタマイズすることに弱い
- 「ログをこうしてほしい」と伝えても自由にカスタマイズするのが難しいようでした。
- Djangoのloggerに関してはSREが実装しました。
OSSにPRを出すのに弱い
- 実装に必要だけど対応してないOSSがあった場合、アップデート待ちでした。
- 全然更新されず、SREがPRを出してたりしました。
これらの原因は技術力ではなく、言語/フレームワークと技術力のミスマッチだと思ってます。
「ある程度フレームワークを使わない実装をGoで書き、適材適所でpackageを用いた方が自由にカスタマイズ出来て良い」と私は判断して会社に通しており、新しいサービスではGoを採用しました。
今後はRails, DjangoサービスもGoに移行する予定です。
4. Goを導入するにあたって
まずtodo-apiのboilerplateを作成しました。
SOLID、凝集度、結合度を意識したクリーンアーキテクチャの実装で、CRUDのAPIとそれぞれのテストを書いて、メンバーに解説しました。
新サービスではそれをベースにAPIをメンバーに書いてもらい、batch系は自分が書いております。
それもいずれメンバーに引継ぎますが、シーケンス図、コメントを読みながらテスト環境で実行すればもういけると思います。
またGoのplaygroundリポジトリを作成しました。
- html/templateをどうやって使うか
- 並行処理
- 並行処理中のgraceful shutdown
- spreadsheetの操作
などさまざまなサンプルを用意しました。
またメソッド名に「自明でもある程度コメントを書く」ということをしてます。
これはRailsで全くコメントを書いてない運用をした結果、初見者が参入しづらい状態になってたのと、
メンバーに「私が同じことしてもいいか?」と聞いたところ「それは厳しい」と言われたのもあります。
(コメントじゃなくてcommit logやPRに書けばいいだけなんですが、まぁcommit log見ない人もいるし、社内リポジトリならこのほうが分かりやすいですよね)
またGoを導入したことで「なければ作ればいい」という発言がよく出るようになったのは一番の成果だと思います。
5. ドキュメントを減らしてmakeに寄せた
開発環境を用意するためにREADMEを見て、このコマンドを打って...
といったオペレーション系ドキュメントはMakefileに寄せた方が冪等性が担保されます。
make help と打つと、開発やオペレーションに必要なコマンドが出てくるようになってます。
こちらはapiの例。
$ make help dist create .tar.gz linux & darwin to /bin clean このMakefileで利用したファイルを docker image 以外クリアにする clean_all このMakefileで利用したファイルをクリアにする build build build/cross create to build for linux & darwin to bin/ run go run run/binary run binary go/get 特定のパッケージをgo getする go/mod_tidy 不要なgo packageを削除する go/test go test go/create_fixtures fixutresをDBに作る go/test_with_create_fixtures fixutresをDBに作りつつtestする go/test_package 特定のパッケージのみのテストを行う docker/build docker build docker_compose/up compose起動 docker_compose/down compose停止 docker_compose/down_f composeではないけど、dockerで強制停止する. conflict対策 docker_compose/down_all compose停止 + 全てを初期化する docker_compose/rebuild appだけbuildし直す migrate/up migration. docker compose up後に実行できる migrate/down migrationのrollback. docker compose up後に実行できる migrate/create migrationファイル作成. migrations/ にup/downが作成される # deploy系はdeploy.mkで管理してるこっち $ make -f deploy.mk deploy/all docker build/push -> db migrate/seed -> fargate deploy login ECRにlogin build docker build. linux/amd64用にbuildする push docker push to ECR。ENVタグとrevisionがついたタグ両方をpushする deploy 既にあるイメージでfargate deployだけする(dockerbuild/pushはしない) image_check ecrにイメージがあるかチェックする。無駄なbuildを無くすため。 db/migrate db/migrateする
6. メールシステムを新規作成した
前述した通り、RailsのAction Mailerを使ってるとGoでメールを送るシステムがありませんでした。
本当はsendgridを使って運用面もしっかり管理できるような体制にしたかったのですが、期間がなかったので、
SQS -> Lambda -> SESのシステムを作り、GoでSQSにメール用のqueueを送る go-mailer という社内パッケージを作成しました。
// こんなメソッドを用意して使ってます func (m *Mail) SendMail() error { mailer := &gomailer.Mailer{ AwsProfile: m.AwsProfile, AwsRegion: m.AwsRegion, Mail: gomailer.Mail{ To: m.ToMailAddress, From: m.FromMailAddress, Bcc: m.BccMailAddress, Template: gomailer_template.TemplateTest, BodyReplace: map[string]string{ "FullName": m.FullName, }, }, } // SQSにqueueを積む if err := mailer.Send(); err != nil { return err } return nil }
パッケージにメールのテンプレートを保管してるので、Goで送るメールは全てそこに集約され管理しやすくもなるといった意図もあります。
また移行するときSESをus-east-1からap-northeast-1に作り直しました。
7. 新サービス用のバッチを書いた
意識したのは冪等性。
一連の流れがあったとして、コンテナに停止シグナルが送られ際に、最後まで実行してgraceful shutdownしてほしいところはどこか。
何回実行しても同じ結果になるか。メンバーとそこを中心に議論とレビューとサンプルを用意して実装しました。
あとはなるべくローカル開発環境で実行させたく、そこの環境構築も力を入れてたのですが、
開発終わり間際でロジックが変わったりして、そこは今微妙になってますが、改善していきます。
(例えばAWS S3の代替は https://github.com/minio/minio を使ったりしてます)
経営的なところを手伝った
あまり話せないのですが、戦略面で2週間ほど色々と手伝ってました。
正直とてもしんどかったですが、私は言語化が得意だったり、場をまとめてポジティブに進めていくのがうまいんだなと再認識できたので、やってよかったです。
次はどうするか
運用面。ドキュメントやテストコードが足りないのでそこは補填していく気持ちです。
またR&D的にflutterのplaygroundを社内で書き始めてます。
そこも色々と課題があってflutterを一度チョイスしてみてます。
あとは色々勉強する必要があるので、今後も引き続き勉強していきたいと思ってます。
Djangoでコンテナ用にjsonログ出力を実装する

TL;DR
- djangoの標準ログは質素すぎて足りない部分が多かった
- djangoのログ出力をjson形式にするformatterを作成
- healthcheck pathなど、特定URIをログ出力させないfilterを作成
Why?
筆者はdjango初心者ですが、自社サービスで一部djangoを使っており、
「datadog logsにjsonログを流したい」という要件が出てきました。
標準のログ機能じゃ要件を満たせず。。またdjangoのloggingはclassが設定できるので、
「標準でダメだったら自分たちで作ってね」という仕様なのかなぁと思いました。
Why formatter?
formatterを作ろうと思ったのは2つ理由があります。
- ログを出力させても質素なログしかGETできず、http request/response周りのデータが欲しかった点です。 _
- 理由は、json型で出力させて、datadog logsにフィールド認識させたかった点です。
https://b0uh.github.io/django-json-logging.html のようにやるとjsonは出力され、2つ目は解決しそうですが、1つ目が解決しません。
https://docs.datadoghq.com/ja/logs/log_collection/python/?tab=jsonlogformatter をみると
https://github.com/namespace-ee/django-datadog-logger が推奨となってたので使ってみるとこのような出力になりました。
{ "message": "HTTP 200 OK", "logger.name": "django_datadog_logger.middleware.request_log", "logger.thread_name": "Thread-2", "logger.method_name": "log_request", "syslog.timestamp": "2021-12-02T09:10:00.541469+00:00", "syslog.severity": "INFO", "network.client.ip": "172.23.0.1", "http.url": "/hoge", "http.url_details.host": "localhost", "http.url_details.port": 8000, "http.url_details.path": "/hoge", "http.url_details.queryString": {}, "http.url_details.scheme": "http", "http.method": "GET", "http.referer": null, "http.useragent": "curl/7.77.0", "http.request_version": null, "http.request_id": "f44778b6-0e78-433a-a2ca-24d1ae1736a3", "duration": 1774787.9028320312, "http.status_code": 200 }
とても良さそうですが、自由にフィールドを追加したい/フィールド名を変えれたら便利
(その他サービスのログフィールドと一緒にすると検索しやすいから)
だと思って、一からformatterを作成することにしました。
Why filter
healthcheck pathなどはノイズになるため、リクエストが来てもログを出力しないようにしたかったです。
djangoにはfilter機能があったので、それも一から作ってみました。
実装したものを適用した後のログ出力
$ curl -X POST -H "Content-Type: application/json" \ -d '{"Name":"hogehoge", "fugarfuga": "fugaaaaaa"}' localhost:8000/hoge { "middleware": "django_datadog_logger.middleware.request_log", "levelname": "WARNING", "filename": "request_log.py", "status": 404, "duration": 28986692.428588867, "error.message": "Not Found", "host": "localhost", "port": 8000, "protocol": "http", "method": "POST", "path": "/hoge", "query_string": {}, "request_body": "{\"Name\":\"hogehoge\", \"fugarfuga\": \"fugaaaaaa\"}", "user-agent": "curl/7.77.0", "remote_ip": "172.23.0.1", "referer": null, "time": "2021-12-08T12:44:50.447804+00:00" }
How
こちらにプログラムを置いてます。
設定方法
required
httpリクエストを解析するために下記が必要です。
# requirements.txt django-datadog-logger==0.5.0
config/base.py
MIDDLEWARE = [ "django_datadog_logger.middleware.request_id.RequestIdMiddleware", . . . "django_datadog_logger.middleware.error_log.ErrorLoggingMiddleware", "django_datadog_logger.middleware.request_log.RequestLoggingMiddleware", ]
のようにして、django-datadog-loggerをmiddlewareに登録させます。
これは、 logging_formatter.py にhttpの詳細ログを送るためです。
config/logging_formatter.py
format用のプログラムです。 django-datadog-loggerでも足りない必要なログを追加したり、
datadog logsに合わせてフィールド名を変更できます。
最後にjson型に変更して出力して終わり。
config/logging_filter.py
filter用です。
ログの出力をするorしないをジャッジします。主にヘルスチェックなど、有効なURIだがロギングしたくないものに対して行ってます
config/environemnt名.py
LOGGING = { "version": 1, "disable_existing_loggers": False, 'filters': { 'custom': { '()': 'config.logging_filter.Main', }, }, "formatters": { "json": {"()": "config.logging_formatter.Main"}, }, "handlers": { "console": {"level": "INFO", "class": "logging.StreamHandler", "formatter": "json", 'filters': ['custom']}, }, "loggers": { 'django.server': {'level': 'ERROR'}, "django_datadog_logger.middleware.request_log": {"handlers": ["console"], "level": "INFO", "propagate": False}, }, } DEBUG: False
formatにlogging_formatter.pyを設定
filterはlogging_filter.pyを設定
handlerはconsole(コンソールにstdoutとして出力用)の1つだけ作成し、filter/formatterは上記を選択
loggersは2つです
django.server- djangoが生成する標準ログ。質素で使えないため(
"GET / HTTP/1.1" 404 179のようなログ)出力させないようにしてます - level: ERRORにすることで、 上記のログを出さないようにしています
- handlerも設定不要
- djangoが生成する標準ログ。質素で使えないため(
django_datadog_logger.middleware.request_log- httpリクエストを解析したログも出力されるやつ。これをベースにログを生成します
またDEBUG: Trueにすることで、ルーティングしてないURIアクセス時の無駄なログ( Not Found: / )を消しています。
developmentだけTrue推奨です。
Fargateで異常終了したコンテナをLambda(Go)でslackに通知する仕組みをTerraformで管理する

TL;DR
- CloudWatch EventsでECS Cluster内のStatusをwatchする
- Eventsトリガーで、Lambda(Go)を発火しSlackに通知する
- それらをTerraformで管理する
- (弊社はFargateオンリーなのでnamespaceにfargateってつけてます)
どんな感じに通知されるの?

※検証時のexit 0でも通知させたときの画像です
Architecture
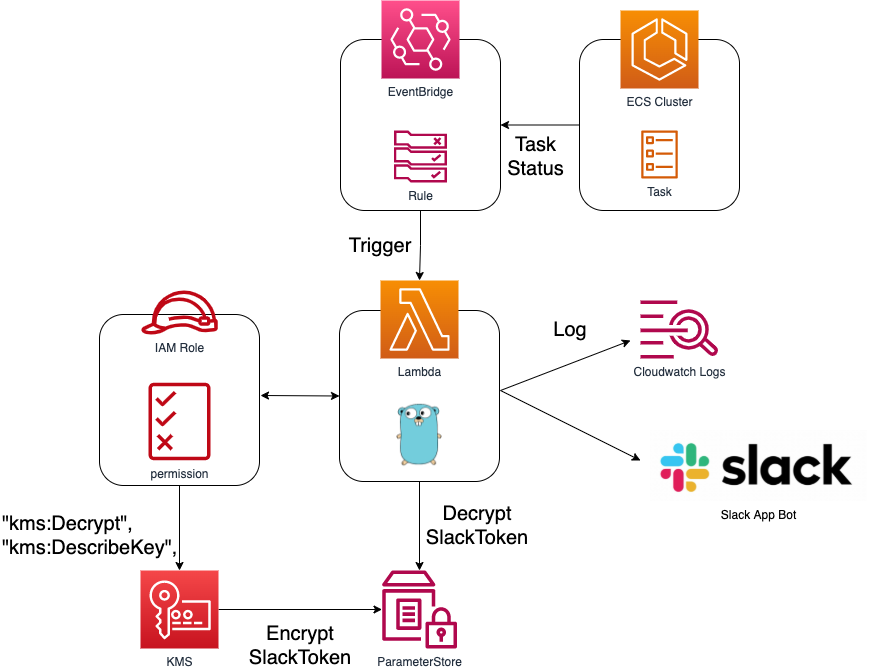
Code
https://github.com/sioncojp/playground/tree/master/terraform/fargate-non-exit-0-notify
実装時のポイント
事前にSlackのappを作る
- https://api.slack.com/apps/
- からアプリを作りましょう
- おそらく下記権限が必要かと思います(OAuth & Permissions -> Scope -> Bot Token Scopes)
- channels:read
- chat:write
シークレット情報はLambdaのEnvironmentに設定できない
- environmentに設定するとコンソールから丸見えになってしまうので、
- コード側でParameterStoreから対象のデータを引っ張る形にしてます
terraformからGoで書かれたlambdaをdeployするのが難しい
- applyする前に
GOOS=linux GOARCH=amd64のバイナリをbuildする必要があります。- もしバイナリがなかったらこけるだけ
- なので一旦ドキュメントでカバーすることにしました。(いい方法あったら教えてください)
Goがインストールされてなくてもbuild, go get -uできるようにした
- Makefileを見てもらうとわかるのですが、
- makeを実行
.go-versionのバージョンのGoをダウンロードし、bin/goとして展開- それを元にbuild -これでどの環境でもbuildできるようにしました
exit 143と0
- docker stopはコンテナにSIGTERM(exit 143)を送信する
- なので基本的に143が返ってくることが多い
- が、tiniやdumb_initでマッピングしてる場合があるのでexit 0も返ってくる可能性がある
- ので両方正常系という扱いをした実装になってます
aws rootアカウントに二要素認証の必要性と有効化する手順
二要素認証の必要性
nullcon HackIM 2020 Writeup - Lateral Movement - こんとろーるしーこんとろーるぶい
こちらのCTF writeupを拝見したところ、下記のような内容でした。
1. script.jsを見て変なHTTPヘッダーを見つける 2. HTTPヘッダーに値をセットしてリクエストを送ると、「値 = EC2ホスト名」でホスト名にリクエストを転送することが判明 3. メタデータにアクセスする「169.254.169.25」にリダイレクトする踏み台サーバを用意 4. 踏み台のグローバルIPをセットしてリクエストを送り、メタデータ取得 5. IAMアクセスキー取得 6. 他のIAM Userに昇格してpassword書き換え 7. そのUserでawsコンソールログイン -> 権限がある部分は操作できる
フラグを盗まれる側の立場になってみると、
このような脆弱性を持ったヘッダーは開発時の設計&レビューで考慮するとしても、完璧に防げそうにはないなと。
「iamに UpdateLoginProfile を不必要にセットするな!」というのはおっしゃる通り。ですが、ログインされる手前の最終防御として二要素認証があれば防げそうだなぁと思いました。
「今時代、二要素認証が必要」ってのは理解しているものの、具体的になぜ必要なのか、というのをこのwriteupで理解できたことがとてもよかったです。
rootアカウントに二要素認証を有効化する手順


スマホやPC等の単一端末がないと難しいと思いがちですが、1passwordのアプリ(web版じゃないよ!)では二要素認証を有効化することができます。
アプリ側で有効化した後は、右画像の通りweb版でも利用可能になります。
あとはrootでログインし、こちらの手順を参考にしてみてください
仮想 Multi-Factor Authentication (MFA) デバイスの有効化 (コンソール) - AWS Identity and Access Management
AWS S3の特定パスにある大量のオブジェクトをGoで並列に別バケットに移動する
チカクのまごちゃんねるというサービスでタイトルのような作業があったので、 そのとき使ったコードのサンプルの共有と背景を若干伏せて紹介してます。 記事を見て、何か良い知見があれば教えてください! bucket/ に1 ~ Nの連番(id)があり、その配下には共通したディレクティブ(a ~ d)が入ってます。 aディレクトリにaa/bbというディレクトリがあり(もしくは片方ない)、その中にオブジェクトが入ってる状態です。 今回は「bucket/{id}/a/aa」「bucket/{id}/a/bb」の中身を全部他のバケットに移す作業です。 無限にオブジェクトが増えていくバケットだった lifeycleで適用しようと考えたが、特定パスが相当な数があったためlifecycleの上限(1000)を超える。またlifecycleは正規表現が使えない issueに切って頭出し。会議の内容や作業手順が全てissueに残していきました。 PdM/サーバサイド/その他関係するエンジニアに進捗、実行するタイミング、スポットでかかったコストや予想されるコストなど変化する事象を密にコミュニケーションしながら進めてました。 まずトップ10あたりのidに対し、対象の容量の比率を出しました。 そして全体に照らし合わせ、どれくらいの容量とコストがあるのかを出しました。 次に 取り出す頻度を加味して あとで紹介するのですが、 社内ロジックを伏せてサンプルコードを載せてます。 最初はawscliでやろうとしたのですが、オブジェクトをGETするだけでも全然終わる気配がなかったので、Goで並列化するしかなかったです。 色々あって3日後にstg。5日後にprod実行だったので、1日くらいでベースは出来て、そこからいろんな要望(flag見るとわかるかと)が出て少しずつ修正していった感じです。 社内にGoに精通した人がそんなにいないので、2日目にmeetsでリアルタイムにロジックを説明してレビューしてもらいました。 今までsyncパッケージのWaitGroupで並列化してたのですが、今回はgolang.org/x/sync/ を使ってみてとてもわかりやすくて良かったです。 golang.org/x/sync/ を使ったGoの並列処理 - Sionの技術ブログ 30並列で、copyが2,3日。deleteが6時間かかりました。 実行時にはアラートチャンネルと顧客からの問い合わせチャンネルを見て、問題がないか確認してました。 まず上記のbashを作り、 終わった時のslack通知には https://github.com/catatsuy/notify_slack を使いました。 2つファイルを作って こんな感じの通知が来てくれました。 Amazon S3 の AWS 請求および使用状況レポートを理解する - Amazon Simple Storage Service 移動時は$8200ほどかかりましたが、移動後は70%のコスト削減ができました。(具体的な数字は伏せてますが、すぐペイ出来る計算になります) 特にかかったのが、いつでもrollbackできるように 通信費に関しては、EC2上で動かしたので無料です。 初期コストはある程度かかるのは分かってたものの、プロジェクト進める前に具体的な数字を出した方が良かったですね。反省。 t2だとネットワーク。c5.largeだとメモリ数(OOM Killer)。 それぞれ並列(30)に耐えれなくてc4.4xlargeにしました。 src/destのオブジェクト自体の比較をしてより精度を高めたかったのですが、 https://github.com/google/go-cmp 使ってみたが、行毎で差分が出てほぼ全部差分になり思ったdiffにならず。 色々あって時間が足りなかったので、トータルオブジェクト数の一致性と、軽く目diffだけでOKと判断しました。 コードは若干diff実装の名残りが残ってるかもしれないです。 https://aws.amazon.com/jp/premiumsupport/knowledge-center/s3-resolve-503-slowdown-throttling/ 実行者側でリクエスト制御するまで、aws側でslow downエラー(制限をかける)を返す事があるらしい。 雑に並列数(30)に下げて対応しました。 上記エラーが発生し、どうやらmapを並列で取り扱う場合はmutex.Lock / Unlockが必要だったということ。 まぁそれはそうだよねという感じで実装しました。 ref: mapの競合状態のはなし - 今川館
はじめに
TL;DR
DeepArchiveにして70%削減できたよバケット構成
# bucket
bucket/
├── 1
│ ├── a
│ │ ├── aa
│ │ │ └── hoge.txt
│ │ └── bb
│ │ └── fuga.txt
│ ├── b
│ ├── c
│ └── d
├── 2
│ ├── a
│ │ └── bb
│ │ └── piyo.txt
│ ├── b
│ ├── c
│ └── d
.
.
.
└── 10000
│ ├── a
│ │ │ └── foo.txt
│ │ └── bb
│ │ └── bar.txt
│ ├── b
│ ├── c
│ └── d
Why
移動?
STANDARDで保存してた
STANDARD_IAにしたが、それでもめちゃくちゃコストかかってたので、特定パスをDeepArchiveにすることでコストカットを提案How
進め方
コストの洗い出しとGlacier or DeepArchive
Glaicer/DeepArchiveにしたときの、もし全オブジェクトを取り出した場合のコストを試算したところ、5.3ヶ月に1回取り出すのであれば、DeepArchiveの方が安いことがわかりました。取り出しコスト =
標準データ取り出しリクエスト(オブジェクト数 / 1000件 * お値段)
+ 取り出し(オブジェクト数 * お値段)
+ GET(オブジェクト数 / 1000件 * お値段)
+ COPY(STANDARD_IA等にコピー。オブジェクト数 / 1000件 * お値段)
※1000件ごとに値段がかかる。お値段はGlacier/DeepArchiveで違う
ref: https://aws.amazon.com/jp/s3/pricing/
DeepArchiveにしたほうが圧倒的に安いという判断になりました。DeepArchiveにする初期コストを試算しておくと完璧だったと思います。コード
どれくらいかかった?
障害が起こってないかの確認
終わったときのslack通知
$ vim run.bash
#!/bin/bash -
date > /tmp/s3.log
./bin/s3-move-other-bucket --src src_bucket --dest dest_bucket --parallel 30
echo $? >> /tmp/s3.log
date >> /tmp/s3.log
nohup /bin/bash run.bash & でバックグラウンドで動かしました。$ vim hoge.toml
[slack]
url = "https://hooks.slack.com/services/xxxxxxxxxx"
channel = "#channel名"
interval = "1s"
$ vim watch.bash
#!/bin/bash -
while true
do
ALIVE=`ps auxww | grep "/bin/bash hoge.bash" | grep -v grep | wc -l`
if [ ${ALIVE} = 0 ]; then
echo "<@Uxxxxx> スクリプト終わったよ!" | /home/ec2-user/notify_slack -c /home/ec2-user/hoge.toml
break
fi
sleep 10
done
nohup /bin/bash watch.bash & でバックグラウンドで動かしました。
移動時と移動後の値段
STANDARD_IAのままコピーして、lifecycle適用で一気にDeepArchiveにしたので、そのときのAPN-EarlyDelete-SIAが$4000かかりました。起こった問題について
1. インスタンス耐えれなかった問題
2. オブジェクト自体のdiffは諦めた
3. Aws::S3::Errors::SlowDownエラー
4. Go側の並列時にmapの取り扱い
fatal error: concurrent map read and map write