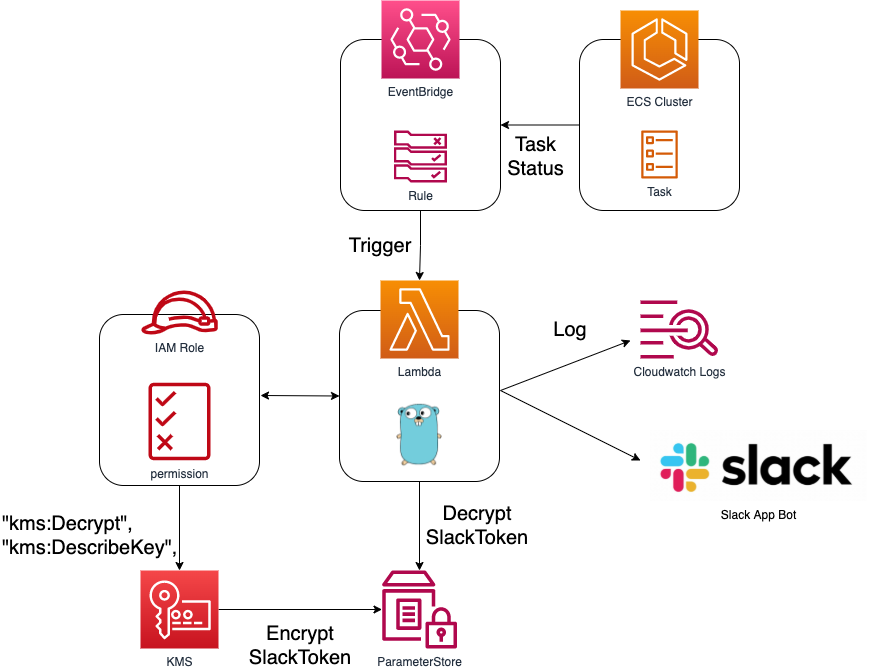
CTOになって1年くらい経ったので実際に実務何をやっているのかというあたりを話そうと思ってます。
会社の戦略、経営に関するものは https://note.com/sion_cojp/ にどこかで書きます。
- TL;DR
- なんの会社やってるの?
- コードは書いたり書かなかったりしている
- PdMを一時やっていたが辞めた
- スクラム開発をやめたけど、また始めた
- デザインをやっていたがやめた
- はじめてのFigma
- 全部署、全メンバーのマネジメントと業務をしている
- ビジネスモデルを確立するために
- 経営チームとして
- 実務
- 最後に
TL;DR
- メインプロダクトは設計・レビューのみ、その他部署のためのコードを書いてる
- PdM + デザインをやったけど権限委譲していってる
- 全部署、全メンバーのマネジメントと業務をしている
- ビジネスモデルを確立するために、全部署のプロセスを作っている
- 会社や事業の思想・戦略を立てて実行していってる – 実務は全ての部署の作業をやっている
- やはりスタートアップは楽しい
なんの会社やってるの?
シスクルという、情シス代行サービスと、それに付随したSaaSの提供を行ってます。
情シスがいる or いない会社でも、我々が「御社の従業員の1名のように、情シス業務(IT業務)を行います」
初期費用なし + 従量課金で提供しているので、是非お問い合わせください
コードは書いたり書かなかったりしている
最初はメインプロダクトとなるSaaS(Go x GraphQLとNext.js)のコードを書いてましたが、最近SaaSは他メンバーに移譲し、CTO兼ドメインエキスパートとして設計に関わるようにしてます。
権限委譲したのは、私のタスクが過多になっているのと、開発チームで顧客の課題を提供するので、それを考えてもらいたいためですね。
コードは引き続き書いており、様々な部署で必要なコード(Chrome Extension(React)やツール(Go))を書いています。
PdMを一時やっていたが辞めた
辞めた理由は、ある程度ベクトルを示せた + 他の職責をやる必要があったので権限委譲したからです。
基本的には https://productschool.com/resources/templates にあることを取捨選択してやってただけで、
大事なのは「現場の負担を抑えながら、正しく推進力を出すこと。情報は自身でPullして把握すればいい」と思ってやっていました
下記のようなPRDテンプレートを用意し、それに沿って書いて進めていた結果、認識齟齬が圧倒的に減ったので良かったです。
特徴的なのは、PRDの段階でBack/Frontで切るべきチケットまで定義してるところですね。途中で必要になったら別途切ってもらえればいいです。
なぜそこまで細かくやっていたかというと、「情シスという難しいドメイン + 初期はこれくらいやらないと推進力がなかったから」です。
1. 概要
2. 目的
3. 別サービスの参考画像/動画
4. SLI
5. ユーザシナリオ
7. 機能でやること
- frontend
- backend
8. 機能でやらないこと
9. Design/UserFlow
10. Q&A
11. Reference
スクラム開発をやめたけど、また始めた
上に付随するのですが、スクラムを一時期やめてトップダウンにしました。
理由とやった結果は下記
# 理由 - 業務委託が中心なので、工数があまり測れない - スクラムに関わる会議を減らして、エンジニアの稼働を増やしたい - スクラムのメリットを感じてない。むしろ負荷 - 情シスという難しいドメイン + 初期はこれくらいやらないと推進力がなかった # やった結果 - 推進力が上がった: PRDベースにgithub issueにチケットを切っているので、あとはやるだけ。 - 早めに問題が発見出来る: コミュニケーションで解決し、迷ったときの最終ジャッジはPdMの私。 - 見積もりはしにくい: 細かく見積もるメリットが当時なかった(流石に遅いと突っ込んでます)
最近になって権限委譲を行い、再びスクラム体制に戻しました。
理由はある程度軌道に乗ったので、そのほうが顧客の課題に最短距離で解決でき、また開発メンバーに顧客のペインに向き合ってほしかったからです。
どう顧客のペインをコミュニケーションするかは、専用のslackチャンネルを設け議論しあう仕組みにしました。

デザインをやっていたがやめた
やめた理由はある程度大枠が出来たから、あとはどういうUIにするかは現場に任せました。
細かくFigmaでデザイン設計すべきだとは思いますが、私の工数が足りないので諦めたのもあります。
なのでFigmaのデザインは頭出し移行updateされてないです。
私がやったことは、MaterialUIベースでSaaSをデザインを一から作り直しました。
「どんなUIになるのか?」最初はmiroで適当な下書きをしていましたが、下記課題を解決するため、私がFigmaで作ることにしました
- プロダクトを円滑に進めるため、もっと細かいレベルのデザイン設計が必要だった - チームからあったほうがやりやすいと言われた - 事業ドメインの複雑性が起因
はじめてのFigma
ぶっちゃけFigma触ったこと無いので、勉強しながら2~3週間くらいで設計完了しました。
Material Designってワードだけは知ってたのですが、完璧に理解できてなかったので、ドキュメントとFigma Communityのテンプレートを利用 + 社内の精通者に進捗報告しながら勉強していきました。
当時は現場から「良さそうに進んでる」と評価いただいてます。
また今回からMaterial Design 2 x MUI → MaterialDesign 3 x Tailwindに変わったので、カラースキーマやテキストもTailwindデフォルトベースにしました。
そこら辺の技術背景、選定、このFigmaの存在意義などは、FigmaにIntroductionページを用意し、全部書くようにしてます。
storybookと連携しないといけないと思いつつ、そこはちゃんとしたデザイナーが雇えたら考えていいでしょう。
色やボタン、ナビゲーションの定義、またそれぞれをコンポーネントで一元管理し、修正しやすいを意識してましたね(色変えたら全部変わるみたいな)



全部署、全メンバーのマネジメントと業務をしている
組織を良くするためにマネジメントをする課題があり、私がやっております。
主にOODAベースでやってますが、私のマネジメント手法は深いので、別途どこかで紹介出来ると面白いかと思います。記事書きます。
社内のアウトプットとしては、どう分析し、アクションしているを必要なメンバーに共有し、いずれ担ってくれれば嬉しいなと思ってます。
ビジネスモデルを確立するために
全部署で、どういうプロセスが必要か or 確立する必要があるか。
私が先陣きり、mermaid記法で全て洗い出し、作成し、必要な方々にレビューしてもらってます。
作るのもしんどい作業ですし、レビューもしんどい作業ではありますが、これがビジネスの基盤になるのでしっかりとやってます
経営チームとして
Service Idea Docというものを書き起こしました。
「なぜこの会社、事業が存在するのか?」というものを定義した1枚ページです。
迷ったらここを見ろってやつですね。
会社と事業単位に1つずつ存在します。テンプレートは下記。
1. この記事のゴール 2. Story 3. Purpose 4. Mission 5. NSM 6. KGI 7. TargetUser 8. 戦略 - 長期戦略 - 中期戦略 9. ロードマップ 10. 全員が理解し顧客に説明できるようになるべき資料 11. エンジニア資料 12. その他 13. Reference
あとは戦略を色々考え、予測し、実行に移して入るのですが、それは sion_cojp|note にでも書きます。
実務
私の作業としては、今は全ての部署の作業をやっています。
経営、営業、エンジニア、カスタマーサクセス、カスタマーサポート、人事労務、採用...
CEOの@TakumaMukai も同じ感じで、人が足らず頑張ってます。
とてもハードではありますが、スタートアップはこういうものでしょう
最後に
私の気持ちとしては「このタイミングに行けば絶対売れ、いずれ世界が変わる」と確信はしているので、頑張っていきます。
CEOの@TakumaMukaiには大変迷惑かけてると思いますが、アドバイスと方向性を示してもらったり、一緒に色々作り上げていけてることに、とても感謝。
また今いるメンバーも気を遣ってもらったり、会社の成長の一役買っていただいてとても感謝。
そしてやはりスタートアップは泥臭くてハードだけど楽しいなぁという気持ちが強いです。
やるべきことがたくさんありすぎて、もっと人を増やす必要があるので、もし興味がある方は下記JD見て応募いただくか、カジュアル面談しましょう!